Reason, Graphql, Prisma와 함께한 백엔드 여정
Reason과 함께한 백엔드 여정
목차입니다.
그린랩스의 개발팀의 선택 - 함수형 프로그래밍
그린랩스는 함수형 프로그래밍 언어인 ReasonML로 풀스택 개발을 하고 있습니다. Reason은 OCaml이라는 함수형 언어에 문법적 설탕(Syntactic sugar)를 가미하여, BuckleScript를 통해 Node 생태계를 사용할 수 있도록 한 함수형 언어입니다. 그린랩스 웹개발팀의 초기 백엔드 기술 스택은 그래프큐엘(Graphql), 프리즈마(Prisma) 그리고 넥서스(Nexus) 였습니다. 왜 우리가 이런 선택을 했는지 그 배경을 간략히 살펴보고 백엔드 개발의 짧은 변천사를 짚어보겠습니다.
그래프큐엘 (GraphQL)
![]()
(출처: https://graphql.org/ 공식 홈페이지)
그래프큐엘은 단 하나의 엔드포인트를 가지는 API 표준입니다. 매 API마다 endpoint를 가지는 REST 방식과는 달리 그래프큐엘은 그래프큐엘 서버(주로 apollo server를 사용합니다)의 단일 엔드포인트에서 클라이언트의 데이터 페칭 요청을 수행합니다.
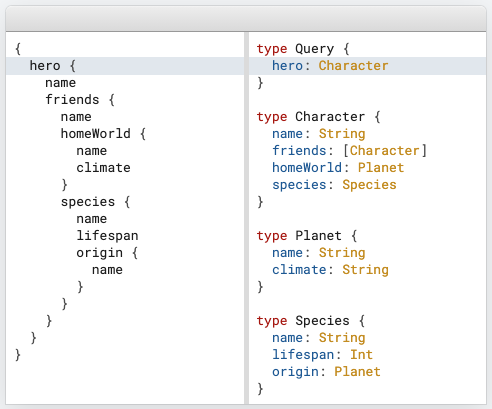
(출처: https://graphql.org/ 공식 홈페이지)
많이 알려져 있는 장점으로는 REST 방식이 가지는 오버페칭(필요 이상으로 많은 데이터를 가져옴)과 언더페칭(필요한 정보의 누락)의 문제없는 유연한 API를 제공한다는 점입니다. 유연하고도 관리 포인트를 줄일 수 있다는 장점에 기반해, 그래프큐엘을 선택했습니다.
프리즈마 (Primsa)
 프리즈마에 대해 간략히 소개하자면 more than ORM 을 지향하는 database toolkit 이라고 할 수 있습니다. 기존의 ORM이 class-interface에 기초한 오브젝트 상세서(specification)에서 출발했다면, 프리즈마는 프리즈마 모델 (prisma model) 이라는 하나의 소스에서 출발하며 항상 Plain Old JavaScript Object를 반환한다는 점이 차이라고 할 수 있습니다. POJO를 반환한다는 점은 함수형 프로그래밍의 철학과 맞닿아 있는데요, DB에서 가져온 데이터가
프리즈마에 대해 간략히 소개하자면 more than ORM 을 지향하는 database toolkit 이라고 할 수 있습니다. 기존의 ORM이 class-interface에 기초한 오브젝트 상세서(specification)에서 출발했다면, 프리즈마는 프리즈마 모델 (prisma model) 이라는 하나의 소스에서 출발하며 항상 Plain Old JavaScript Object를 반환한다는 점이 차이라고 할 수 있습니다. POJO를 반환한다는 점은 함수형 프로그래밍의 철학과 맞닿아 있는데요, DB에서 가져온 데이터가
- 시간이 지나도 값이 변경될 우려가 없고
- 스레드 간, 또는 캐시 내에서의 값 공유가 쉬우며
- 복사의 비용이 적게드는
장정이 있습니다.
이에 대해서는 후에 적힐 프리즈마 관련 포스팅에서 더 자세히 다뤄보겠습니다. 프리즈마는 또한 편리한 여러 migration 기능(기존 DB에서 모델을 뽑아오는 introspect, 모델 기반 DB를 구성해주는 migrate, DB의 값을 편리하게 조작할 수 있는 studio)을 제공하기도 합니다.
넥서스(Nexus)
 넥서스는 코드 우선(code-first)의 가치를 기본으로 만들어진 라이브러리입니다.(https://www.prisma.io/blog/the-problems-of-schema-first-graphql-development-x1mn4cb0tyl3) 그래프큐엘 리졸버와 데이터 모델링 정의를 한곳에서 하며, 동적으로 graphql 스키마를 생성하는 역할을 합니다. 그래프큐엘-프리즈마 스택에 어울리는 라이브러리라고 생각했으나, 실제로 사용하면서 생각이 바뀌었습니다 (뒤에 설명되어 있습니다).
넥서스는 코드 우선(code-first)의 가치를 기본으로 만들어진 라이브러리입니다.(https://www.prisma.io/blog/the-problems-of-schema-first-graphql-development-x1mn4cb0tyl3) 그래프큐엘 리졸버와 데이터 모델링 정의를 한곳에서 하며, 동적으로 graphql 스키마를 생성하는 역할을 합니다. 그래프큐엘-프리즈마 스택에 어울리는 라이브러리라고 생각했으나, 실제로 사용하면서 생각이 바뀌었습니다 (뒤에 설명되어 있습니다).
함수형 프로그래밍과 타입 시스템
드디어 개발팀의 첫 과제가 나온 시점. 백엔드 개발에서는 넘어야 할 산이 있었으니 바로 타이핑(typing) 이었습니다. 내부에서 ‘퍼즐 맞추기 같다’라는 이야기가 나올정도로, Reason의 타입 시스템은 엄격한 작업을 필요로 했습니다. 간략히 함수형 언어와 타입 시스템이 어떤 관계에 있는지 알아보겠습니다.
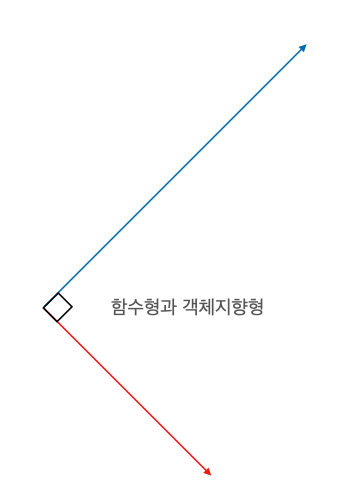
함수형 프로그래밍은 객체 지향 프로그래밍과 직교(orthogonal)하는 관계입니다. 세상을 모델링하는 방식에 있어 함수형은 부작용(side-effect)가 없는 코드를 작성하는 것에, 객체지향은 동작 추상화(behavioral abstraction) 초점을 맞추고 각기 발전해 왔습니다.
강력한 정적 타입 시스템을 갖는 것이 함수형 언어의 필수조건은 아니지만, 부작용을 최소화하는 목적에 잘 부합합니다. 강력한 타입 시스템은,
- 컴파일 시간에 많은 오류(스트링값을 곱하거나 뺀다거나 하는 등)를 잡아줄 수 있습니다.
- 커리-하워드 정리에 의해 그 자체로 논리적 명제를 증명할 수 있습니다. 따라서 잘 짜여진 타입 시스템에서는 논리적으로 잘못된 프로그램이 작성될 수 없습니다(cannot-go-wrong program).
여기서 잠깐. 타입은 C나 자바같은 무수히 많은 언어들이 가진 특징인데, 함수형 언어에서만 특별할까요? 그럴수도, 그렇지 않을 수도 있습니다. 자바에서 String을 리턴하는 함수를 예로 들어보겠습니다.
public String hello(String input){
String output;
/*
input을 사용하는 비지니스 로직
*/
return output;
}
이 hello라는 함수가 리턴할 수 있는 값이 과연 엄격하게 String일까요? hello가 반환하는 값은
- 스트링
- null
- 예외 (exception)
- 반환을 못함 (무한 루프등에 빠져) 등등의 의도하지 않은 경우가 많음을 알 수 있습니다. 하지만 정적 타입 시스템을 가진 함수형 언어에서는 스트링을 반환한다고 하면, 컴파일러를 잘 통과했다는 전제하에 문자 그대로 스트링을 반환함을 보장받을 수 있습니다. 타입 시스템은 개발자로 하여금 사용하는 대상에 대한 명확한 이해와, 코드의 무결성을 지원함으로써, 부작용없는 프로그램을 만드는데 도움을 주는 것이죠.
첫번째: 시도
첫번째 업무는 도매출하 신청을 받기위한 백엔드 구축이었습니다. 유저가 입력한 값을 받아 DB에 저장하는, 정말 기본중의 기본이었지만 Reason 작성하기 위해선 다음의 과정을 거쳐야 했습니다.
- GraphQL 서버 바인딩 - 서버 함수(new, start), schema와 context 정의
- Prisma 바인딩 - client 생성, CRUD 함수, prisma object의 내부 값들 정의
- Nexus 바인딩 - nexus 함수, 함수들의 인자, nexus플러그인
바인딩이란, 이미 존재하는 JavaScript 라이브러리에서 타입 없이 쓰이고 있던 모든 함수 및 객체들을 Reason에서 사용하기 위해 각 함수의 인자와 반환값을 정의하고. 객체에 레코드 등의(record) 타입을 부여하는 작업을 뜻합니다.
예를 들어 nexus 바인딩을 위해선 아래와 같이 타입을 정의하는것이 먼저 필요합니다.
type nexusSchema
type mutationField
type queryField
type nexusObjectType
type nexusSchemaPlugin
type nexusSchemaPath = {
schema: string
}
type nexusObjectTypeOptions = {
name: string
definition: Prisma.prismaObject => unit
}
타입을 정의한 후에는 이 타입을 반환값 혹은 인자로 가지는 함수들에 대한 정의를 해줘야합니다.
type nexusObjectTypeOptions = {
name: string
definition: Prisma.prismaObject => unit
}
@bs.module("@nexus/schema")
external objectType: nexusObjectTypeOptions => nexusObjectType = "objectType"
@bs.module("@nexus/schema")
external mutationField: (~name: string, NexusResolver.mutationResolver<'argsType, 'prismaArgsType, 'instance>) => mutationField = "mutationField"
@bs.module("@nexus/schema")
external stringArg: argOpts => string = "stringArg"
이렇게 사용하고자하는 라이브러리의 모든 함수와 인자, 객체들을 바인딩해야 했던 것이 극초기 백엔드의 모습이었습니다. 단순한 request라는 모델의 CRUD를 위해서 작성해야하는 코드의 양이 굉장히 많았고, 내부적으로 과연 이 방법이 지속가능한가에 대한 의문이 생겼습니다.
여러 회의를 통해 문제를 두 개로 정의했습니다.
첫째는 Graphql을 통해 요청되는 다양한 argument들에 대한 타이핑을 하나하나 해줘야 하는 것에 관한 것이었습니다.
type User = {
id: string,
name: string,
farm_id: int,
address: Address,
phone_number: string,
};
Graphql에서는 이렇게 정의된 User에 대해 id만 물어볼수도, (id, name)을 물어볼 수도, (id, address, phone_number)을 물어볼 수도 있습니다. n개의 필드에 대해 2^n-1 개의 조합이 생길 수 있는데, 문제는 Reason에선 이 조합을 하나하나 타입으로 만들어줘야 했습니다.
//id 만
type user1{
id: string
}
//id, 주소, 전화번호만
type user2{
id: string,
address: Address,
phone_number: string
}
이런 식이었습니다. 물론 Option으로 값을 감싸서 null 일 수 있음을 표현할 수 있었지만, 그것도 문제가 있습니다. null 일 수 있음을 용인하면 프론트단에서 오는 값이 정말 null로 보낸건지, 아니면 잘못된 요청이 온 것인지 구분할 수 없습니다.
또한 Option으로 표기된 값이 비어있을 경우 JavaScript에서는 undefined로 변환되는데, GraphQL이 의존하고 있던 라이브러리에서 객체안의 필드값이 undefined인 경우 오류를 뱉어내는 경우가 존재했습니다. 이를 핸들링하기 위해선 또 다른 전략이 필요한 상황이 된 것이죠.
두번째 문제는 프리즈마와 넥서스단의 바인딩량이 너무 많다는 것이었습니다. 그에 앞서, 타이핑 안정성보다 타입 안정성이 어떤 결과를 가져오는지를 생각해보면, prisma와 nexus 단의 바인딩은 라이브러리를 엄격하게 사용하는 것과 관련되어 있었습니다. 즉, 바인딩을 통해 나는 프리즈마(또는 넥서스)를 요구하는대로 사용했다 - 라는 결론을 얻는 것인데, 이것이 우리가 추구하고자 하는 방향과 맞는가하는 의문이 있었습니다.
두번째 - 과도기:
빠른 대응이 필요한 시점이었기에, 우선은 첫번째에서 했던 시도를 중단하고 순수한 JS로 돌아가 개발하기로 일시적으로 합의하였니다.
함수형 백엔드 개발에 대한 방향성은 그대로 가지며, 팀 내부적으로는 [Thinking with Types : type level programming in Haskell / Sandy Maguire 저], [Web development with ReasonML / J.David Eisenberg 저] 등을 열심히 읽으며 토론하며 돌파구로 GADT (Generalized Algebraic Data Type)를 염두해두고 공부해나갔습니다. 이 시기 회의를 통해 아래와 같은 결론을 얻었습니다.
GraphQL 관련해서..
정말 타이핑이 필요한 부분은, 프론트엔드 -> 백엔드 로 넘어오는 GraphQL 인자입니다.
let createParam: NexusResolver.mutationResolver<NexusResolver.speciesQuantity, NexusResolver.userIdSpeciesQuantity,'b> =
{
_type: "request",
args: {
kind: stringArg(""),
quantity: stringArg("")
},
resolve: (_, args, { req, prisma }, _) => {
// 이 부분에서 비즈니스 로직을 수행할 때 타입 세이프함이 중요합니다.
prisma.request->create({
data: {
kind: args.kind,
quantity: args.quantity
}
})
}
};
위의 예시를 보면, resolve 부분의 args에서 꺼낸 값들을, prisma의 인자로 넣기 전 args.kind, args.quantity 로 꺼내는 것을 볼 수 있습니다. 만약 prisma로 가기 전 어떤 로직을 수행해야 한다면, 서로의 타입을 고려한 연산이 이뤄져야 할 것입니다. (Int에 String을 더하거나, TimeStamp에 Float을 곱하는 등의 일이 없어야합니다)
이 부분이 백엔드 타이핑 중 가장 핵심적인 부분이라는 것에 동의한 후, 나머지 기술 스택에 대한 바인딩을 생각해보았습니다.
프리즈마에 대해서
프론트단에서 들어오는 값들에 대한 Null 값 처리 및 타입 확인은 GraphQL에서 이뤄지고 있음을 확인했습니다. 여기서 Prisma Client가 쓰게 될 인자들에 대한 타이핑을 다시 하는 것이 의미있을까요? GraphQL에서 정의한 타입을 다시 정의하는 것밖에 되지 않는다고 판단해 Prisma의 인자들에 대해서는 Record가 아닌 Object를 사용하여 타입 체크를 하지 않기로 했습니다. ReScript의 Record와 Object에 대해선 공식문서를 참고하시면 좋을 것 같습니다.
넥서스에 대해서
그 다음 고민은 과연 Nexus가 필요한가 였습니다. Nexus에 대한 바인딩은 넥서스를 얼마나 잘 사용하고 있는가를 체크하는 행위로, 그걸 사용하는 입장에서 많은 시간과 노력을 들여가며 엄격히 다뤄야 할 필요를 느끼지 못했습니다. 나중에 더 자세히 다루겠지만, Nexus의 코드 우선(code-first) 개발에 대해서도 원론적인 회의감이 생겼습니다. 그래서 과김히 걷어내기로(!!) 결정했습니다.
세번째 - 해결책 :
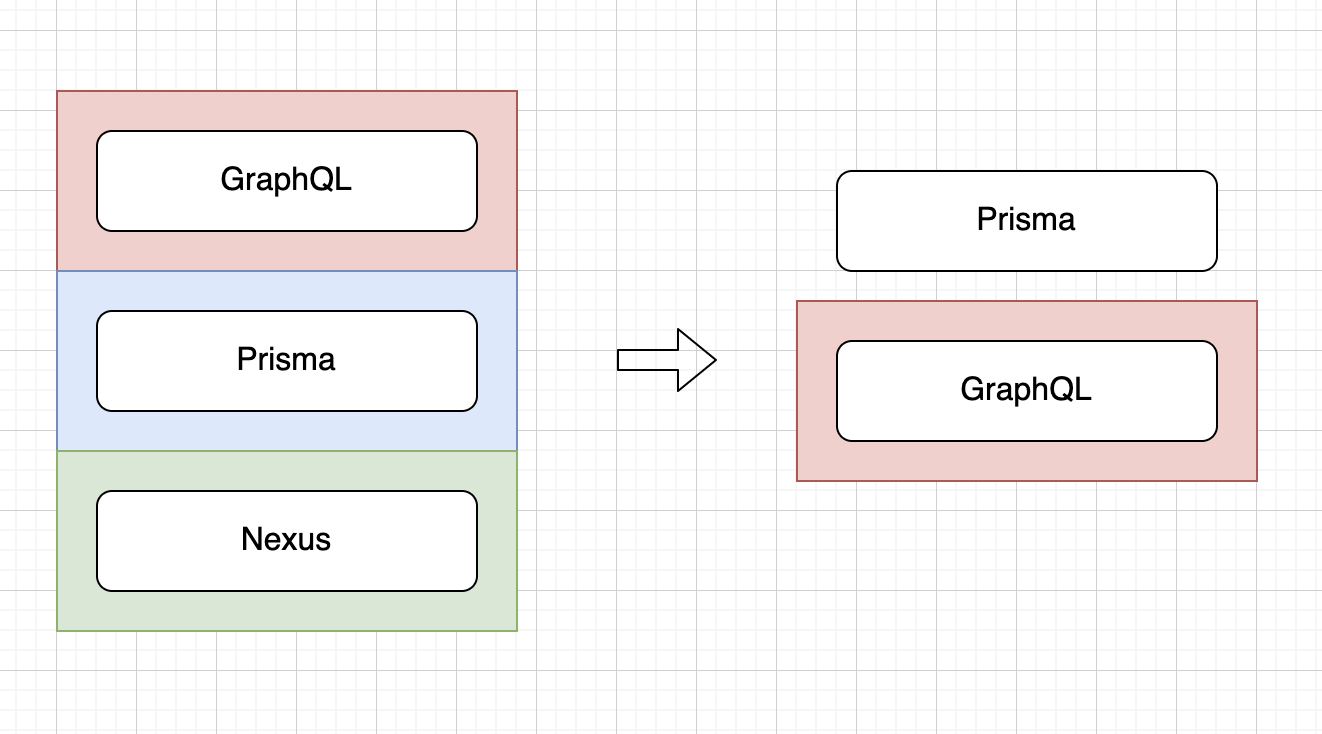
그렇게 해서 최종안이 탄생했습니다. Nexus 부분의 로직을 전부 걷어내고, Prisma에 대해서는 Record가 아닌 Object를 사용하기로 했습니다. 클라이언트에서 넘어오는 GraphQL 입력값(Input)에 대한 부분은 이전처럼 Type을 명시한 Record로 표기하기로 했습니다.
이렇게 결정한 후의 이점은 다음과 같습니다.
- 의존하고 있는 라이브러리가 줄고, 바인딩해야 할 대상이 적어져 개발시간이 현저히 단축되었습니다.
- 여전히 ReScript의 타입 시스템을 활용해 프론트엔드 단에서 넘어오는 데이터 조작 시 타입 안정성을 보장받을 수 있게 되었습니다.
- 결론적으로, ReScript의 엄격한 타입 시스템을 잘 활용할 수 있는 부분에만 적절히 적용하고, 나머지 부분은 개발 속도 및 합리적인 유지보수를 위해 사용하지 않기로 했습니다.
이렇게 해서 함수형 언어, ReasonML과 ReScript를 사용한 그린랩스의 백엔드 개발은 첫 발을 내딛게 되었습니다. 곳곳에 혁신이 필요한 많은 다양한 업무들이 기다리고 있는데요, 언어가 발전하고 우리의 이해가 깊어지면서 앞으로는 더욱 새롭고 풍부한 함수형 개발이 있을 예정입니다!